
Just over a week after Copy Fail, two more Linux kernel root exploits went public on May 7. They chain into a single primitive called Dirty Frag, and any unprivileged local user can use it to gain root on essentially every mainstream Linux distribution. If you run Linux at scale, you almost certainly need to patch.
The question every kernel disclosure produces is always the same: are we affected, and where? For most teams, the honest answer is "give us a few hours." Sometimes a day. Often longer.
The PoC is public. The exploit is deterministic — no race conditions, no kernel panics, very high success rate. The clock is the patch rollout against the attackers who already have the code.
The hours you don't have
Kernel maintainers do their part. Distro security teams do theirs. CISA eventually catches up. Between those events you have a window measured in hours or days where:
- Your VMs, container hosts, and Kubernetes nodes are running a vulnerable kernel.
- Your security feed is on fire.
- Your stakeholders are asking "are we affected?"
- Someone on your team is running
uname -ragainst a hand-rolled spreadsheet.
The hard part is never "patch it." The hard part is knowing where to patch, fast, before someone proves you missed a host.
For most teams that inventory hunt costs a half-day at minimum: which clouds, which accounts, which regions, which images, which kernel versions, which workloads are sitting on a vulnerable host. Some of those answers don't live in one place. Some require waking an on-call SRE.
When the exploit is deterministic and the PoC is on GitHub, those hours matter more, not less.
How we found out
We learned Dirty Frag was loose the morning the advisory dropped. Not from a security feed. Not from a vendor email. From the same dashboard we look at every morning before opening anything else.
VikingCloud has a feature called Today's Briefing. Every morning it reads the new advisories — kernel mailing lists, distro trackers, security news, CISA bulletins — cross-references them against the inventory it has already collected from your clouds, and tells you in plain English whether you are affected. No CVE math required.
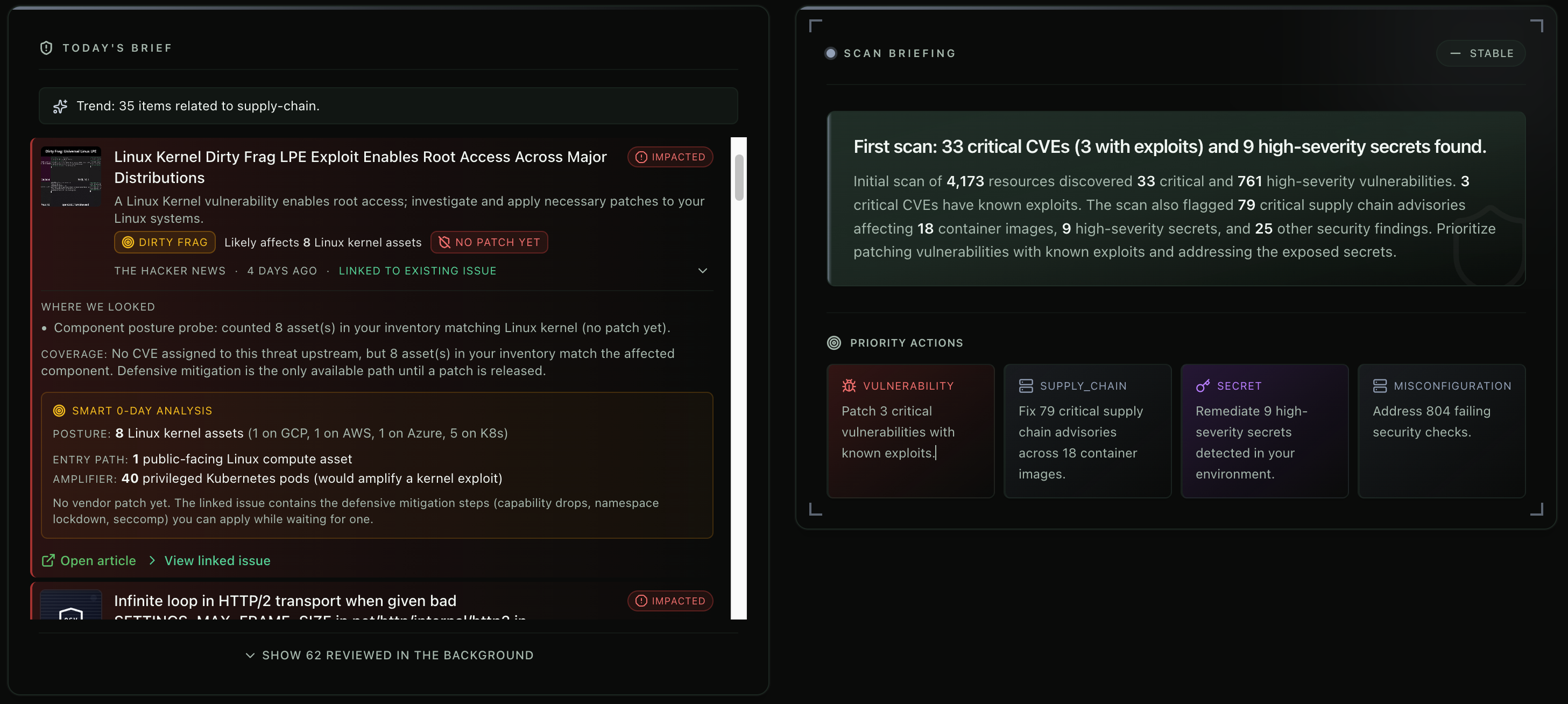
We were affected. Of course we were. Anyone running Linux right now is. We are not pretending we dodged anything. The point is not luck — we are exposed like everyone else. The point is we knew within seconds of opening the dashboard, before most teams could open their inventory script.
What knowing actually buys you
Knowing you are affected is half the answer. The other half is what to do about it, now, before someone else demonstrates they got there first.
The briefing promoted the finding straight into our Issues list — the same place we track every other thing we have to fix. Each Issue carries the affected resources, the MITRE ATT&CK techniques mapped to the threat, an ordered remediation playbook with concrete commands, and the blast-radius assessment that tells you how bad it gets if this one host falls.
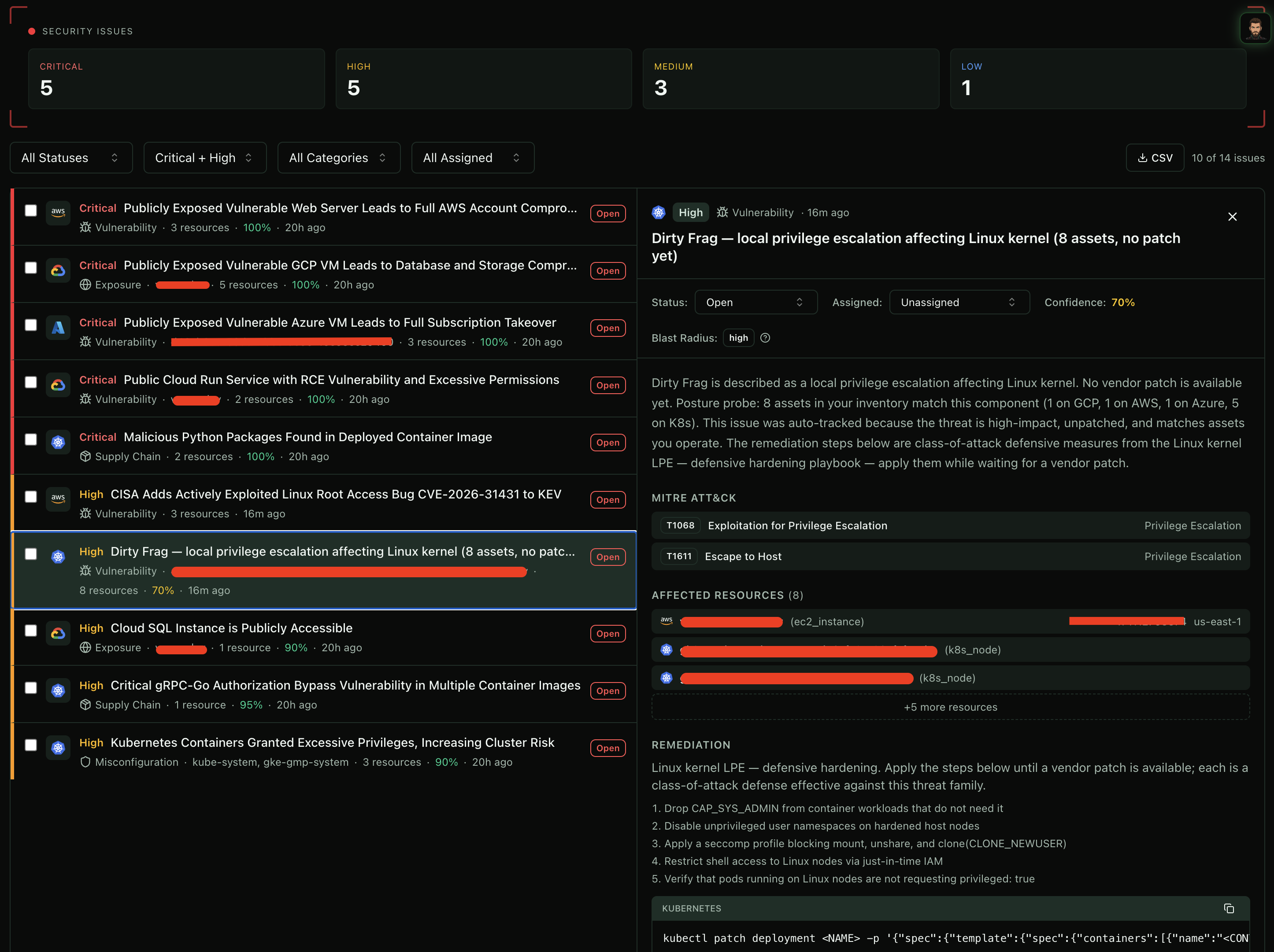
That is the difference between "we are exposed" and "we are exposed and reacting, with a written list of steps and a clock on each one."
What VikingCloud actually does
We will not claim to have prevented Dirty Frag. No external scanner can prevent a kernel logic bug. What we do is collapse the time between "advisory is public" and "we know exactly which workloads are exposed" from a half-day scramble into seconds.
Filesystem-truth, not metadata-truth. When you connect a cloud account, we run an agentless, deep filesystem inventory of every VM. We extract the actually installed kernel package — linux-image-* on Debian and Ubuntu, kernel-* on RHEL and Amazon Linux, kernel-default on SUSE — at its real installed version. Not the AMI's claimed version. Not the launch template. What is on the disk, today. The same approach runs on AWS, Azure, and GCP.
Advisory-to-impact in seconds. Today's Briefing reads new advisories every morning, cross-references them against your already-collected inventory, and tells you in plain English whether you are affected and where.
Pre-correlated KEV, EPSS, and severity. Each affected workload carries its CISA Known Exploited Vulnerabilities flag, its KEV due date, and its EPSS exploit-probability score on the same row as the CVE. The triage spreadsheet most teams build by hand is pre-computed.
One Issue, not one alert per host. Twenty hosts across four accounts running the same vulnerable kernel show up as a single Issue with twenty affected workloads, not twenty duplicate tickets. Each resource carries its account, region, kernel version, and patch availability for its distro.
Pre-patch playbooks included. When the patch is not yet on every host, the Issue carries the kernel-team mitigation guidance — module blacklists, sysctl flags, eBPF rules, monitoring queries — for the gap between disclosure and fleet-wide patch rollout.
What VikingCloud does not do
The honest limits, because they matter more than the marketing:
- We see the installed kernel package, not the running kernel. Our scan reads the installed-package database from the filesystem. If a host has the patched package installed but has not rebooted, we will report it as patched. The "reboot after patching" step is on you, and verifying it landed in the running kernel is your monitoring stack's job.
- Briefings run on a schedule. Today's Briefing checks the advisory feeds on a daily cycle. If a CVE drops at 02:00 and your briefing ran at 01:00, the affected workloads surface at the next cycle. For higher-frequency triage, the underlying scans can be triggered manually.
- We do not have a Dirty Frag-specific detector. We surface CVE-2026-43284 and CVE-2026-43500 the same way we surface every CVE: by package version match against the vulnerability database. There is no special heuristic and there does not need to be.
- We do not detect exploitation in flight. We tell you what is vulnerable and what is exposed. We do not tell you what is being actively attacked. Pair this with an EDR or runtime sensor for the other half of the picture.
If those limits are deal-breakers for your environment, you should know that going in. For the specific job of knowing in seconds which of your cloud workloads is running a vulnerable kernel, the boundary of what we do maps cleanly onto the boundary of what closes the discovery-to-knowing gap.
What this means for your team
Dirty Frag is not the last kernel CVE. It is unusually clean — deterministic, single-command, every major distribution, public PoC, patches released the day of disclosure — but the structural problem it exposes has been quietly sitting under every Linux fleet for years. The question "what kernel is running on each of our hosts, right now, today?" should be a one-second answer. For most teams it is not, and that is the gap worth closing.
If your discovery-to-knowing window is sub-minute, you patch in priority order, you make defensible decisions about what to take out of rotation, you can show your auditor a list, you can tell your CISO honestly whether the company is exposed. If your window is in hours or days, you patch under stress and find out the hard way which hosts you missed.
Driving that window to seconds is not a feature that prevents attacks. It is the operating posture that makes you ungameable by the next CVE drop. That is the fight worth investing in.
What to do today, with or without us
If you have not yet checked whether Dirty Frag affects your fleet, the bare minimum:
uname -ron a representative sample of your hosts. Vulnerable kernels are anything pre-patch-set as of May 7, 2026.- Check your distro tracker for the advisory and apply: Red Hat RHSB-2026-003, AlmaLinux's 2026-05-07 release, Ubuntu USN, openSUSE, Debian DSA.
- For anything you cannot reboot today, blacklist the affected modules:
esp4,esp6,rxrpc. None are typically loaded on workloads that do not use IPsec transport mode or AFS, so the attack surface effectively drops to zero on most systems. - Watch your kernel logs for the indicators security researchers are publishing as they reverse-engineer the public PoC.
If that sounds like a lot of work for an ordinary morning, you understand why we built the briefing.
Start your 14-day free trial to see your VM, container, and Kubernetes inventory cross-referenced against the latest CVE feeds in seconds, or book a demo if you would prefer we walk through the platform with your team.
References
- Tenable. Dirty Frag (CVE-2026-43284, CVE-2026-43500): Linux Kernel Privilege Escalation FAQ.
- Red Hat. RHSB-2026-003 — Networking subsystem Privilege Escalation - Linux Kernel (Dirty Frag) - CVE-2026-43284.
- AlmaLinux. Dirty Frag (CVE-2026-43284, CVE-2026-43500) Patches Released. May 7, 2026.
- openwall oss-security. Dirty Frag: Universal Linux LPE. May 7, 2026.
- BleepingComputer. New Linux 'Dirty Frag' zero-day with PoC exploit gives root privileges.
- Phoronix. Dirty Frag Vulnerability Made Public Early: Root Privilege On All Distributions.
- Heise online. Dirty Frag: Linux flaws grant root access.
- The Hacker News. Linux Kernel Dirty Frag LPE Exploit Enables Root Access Across Major Distributions.
- V4bel. Dirty Frag proof-of-concept (GitHub).